

Introduction
Vector Search utilizes vector search technology developed by Google Research. With Vector Search, you can leverage the same infrastructure that provides a foundation for Google products such as Google Search, YouTube, and Play. Unlike keyword searches, it identifies meaningful connections beyond surface-level differences. This approach works for images, text, code, and various data types, enabling searches based on emotions or functionality rather than specific keywords. It provides a versatile solution for quickly and accurately retrieving information in our data-driven world, improving search experiences across diverse applications.
Distinction Between Text-based and Multi-modal Search
Traditional text-based search engines use keywords to find information, limiting their understanding of user intent. In contrast, multi-modal search incorporates diverse data types, like images, to address ambiguity. Unlike text-based search, it can identify similarities in styles, colors, and brushstrokes in images, providing a more innovative and comprehensive search experience.
This opens up a whole new realm of possibilities, allowing users to search using:
- Images: Find visually similar products, identify objects in pictures, or discover artwork with matching styles
- Audio: Search for music based on mood or genre, identify animal sounds in recordings, or translate spoken languages
- Video: Locate specific scenes within videos based on visual content or spoken dialogue, understand the overall message of a video, or find similar video tutorials.
Here’s a table summarizing the key differences:
| Feature | Text-based Search | Multi-modal Search |
| Data type | Mainly text (keywords, descriptions) | Text, images, audio, video |
| Matching criteria | Keyword-based | Semantics, visual features, audio properties |
| Strengths | Efficient for factual searches, large text corpus | Handles ambiguities, understands complex concepts, visual discovery |
Creating the Spark: The Art of Embedding Generation
Vector search relies on embeddings, which serve as a common language of similarity. These embeddings transform diverse data types such as text, images, and sounds into mathematical representations. The goal is to condense complex information into a single point in a multidimensional space. The various techniques employed include:
Word Embeddings: Analyzing word relationships and context for text, capturing semantic nuances. For example, the relationship between “king” and “queen” is closer than “king” and “apple.”
Image Embeddings: Using Convolutional Neural Networks (CNNs) to extract visual features like edges, shapes, and colors, resulting in an embedding reflecting the image’s content.
Audio Embeddings: Similar to image embeddings but focused on analyzing sound frequencies and patterns to represent audio data’s meaning.
The selection of a technique depends on the data type and desired outcomes. The quality of embeddings directly affects downstream tasks like similarity search
Storing the Treasures: Finding the Right Home for Embeddings
- In-Memory Storage: Ideal for small datasets and real-time applications, but limited by memory capacity
- Databases: Relational databases struggle with high-dimensional data, while specialized vector databases like Faiss or Pinecone are optimized for efficient storage and retrieval
- Cloud Storage Solutions: Services like Google Cloud Storage or Amazon S3 offer scalability and cost-effectiveness for larger datasets.
The choice hinges on factors like data size, access frequency, and budget. Striking the right balance between performance and cost is crucial.
Unveiling the Magic: Querying Embeddings
Now comes the exciting part: using embeddings to find similar items. Querying techniques fall into two main categories:
- Nearest Neighbor Search: This popular method finds the closest neighbors (most similar items) to a query embedding in the multidimensional space.
- Semantic Search: Explores the semantic relationships between embeddings, returning relevant results even if they don’t share exact keywords.
Both techniques leverage the inherent structure of embeddings, uncovering connections that traditional keyword-based methods might miss.
Solution Architecture
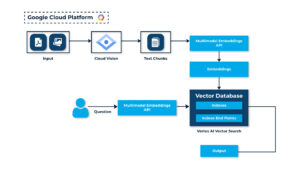
Advantages
Semantic Understanding:
- Goes beyond keywords to understand the true meaning and intent of queries.
- Handles ambiguities and retrieves relevant results even without exact keywords.
- Supports diverse data types (text, images, audio, video) for a more intuitive search experience
Increased Accuracy:
- Identifies deeper connections and meaningful relationships between data points
- Delivers more relevant and accurate results compared to traditional keyword-based search
- Enhances discovery of content not found through conventional methods
Conclusion
Vertex AI Vector Search revolutionizes information retrieval by transcending keyword limitations. Its multi-modal approach, utilizing embeddings for diverse data types, empowers users with semantic understanding, enhancing search accuracy and uncovering meaningful connections. This innovative solution not only transforms search experiences but also adapts to the complexities of our data-driven world, offering a versatile and efficient means of navigating vast datasets.



