

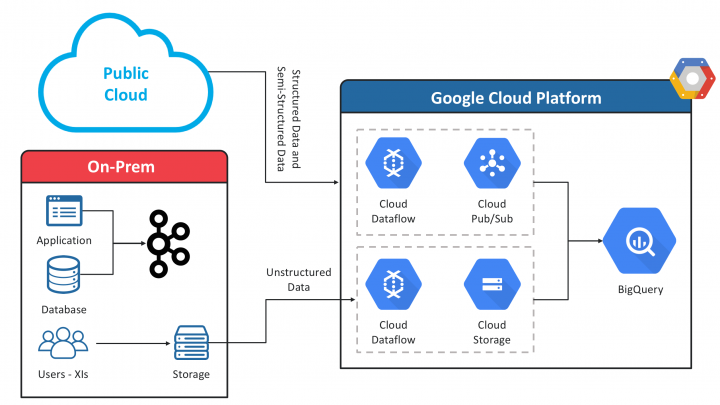
In this world, where enterprises use multi-cloud environments with applications existing on-prem and in the public cloud, there is a need for data exchange both in batch and stream to a platform where the enterprise is planning to build applications.
Application Integration and API’s ?
Another argument can be that if the application can build API’s or already has API’s then what is the need of pulling the data out? Based on this approach what we have observed is that it leads to point to point integration where we need to build API’s from and to this application based on what kind of integration we need to do. Also the application owners are responsible for providing the API, which leads to scalability issues.
Another issue is being able to do consistent reporting on top of the data available in multiple applications and every time we need data we have to write business logic to how to combine the data and transform it based on the needs of reporting or another application. For example, customer, order and inventory reside in multiple apps and it’s tough to bring all of it together by invoking API’s every time, which is dependent on the individual applications not being down for maintenance or other integration issues.
Microservices and Data Lake
Pattern: CQRS – Command Query responsibility segregation
The thought of building a data lake comes from the backdrop on how to effectively remove the above bottleneck of application integration and solve it by bringing in all the data from multiple domains together under one roof.
The data can be structured depending on the source or unstructured like pictures of devices, employees, customers, etc. the idea is to build a consolidated repository of bringing all the DB’s in the enterprise and house them together.
How will this help?
1. In the above solution, the team and BA’s who understand the data can segment the data based on domain coming from multiple sources
2. The data can now be modeled independent of the source and kept in the DB of our choice like (SQL/NoSQL)
3. The dependency of building the API’s can now be more distributed and decentralized
4. There is no need of doing point to point integration, as every one who needs the data(aggregated) can now consume those API’s
5. Better API Management and Security
6. Data is now available for unified reporting
7. Source Applications can now dedicate the resources towards writes vs reads, which helps in increasing performance
8. Doing Machine learning and Analytics on Data Lake will help in solving some of the enterprise use-cases which was not possible before when the data was distributed
Building Connectors/Data extractors
Pattern : Smart endpoints, dumb pipes
When we start with the above challenge the first and foremost challenge is to build connectors or data extractors to pull data from the applications. Based on experience most of the time you have to pull the data directly from the database which the application uses.
The job of the extractors is to pull the data and push it to a Messaging layer/Pub Sub platform (eg. Kafka), the applications can also push or stream the data to the pub/sub platform. These pipelines will not be storing any transformation rules, etc.
Once the data is successfully being posted to a messaging layer it can be streamed to a cloud/platform of our choice to be later pushed to Data Lake – Staging layer.
Building Micro-services
Now we have the data being collected in Stage later, next step is to cleanse, prep, transform, aggregate the data based on domains and store it in a data store which is more suitable based on Data Query/Data Ingestion.
Once we have the data collected for a domain, we can now have a reusable API layer for the data to be available over HTTP/GRPC/GQL/JDBC/ODBC. Most of the API’s are read-only API’s leveraging GET calls only.
Strategy
Following the above strategy of building a Data lake and Micro Services actually speeds up the integration and creates assets which can be leveraged for building applications like Customer 360, Asset Lifecycle, etc. It also helps with MDM strategy, with creating a repository or doing effective reporting, analytics, and machine learning.



Awesome ! Keep publishing .