

In today’s technology-driven world where we handle large amounts of data, speed is crucial. Whether it’s searching through extensive databases or rapidly retrieving information, these tasks must be performed efficiently. One effective approach to achieving this is binary quantization, a technique that enhances the speed and efficiency of these processes.
Vector Databases and Embeddings
Before we get into Binary Quantization, let’s first explore vector embeddings. Imagine three different data types: images, text, and audio. Machine learning models convert each data point into a format suitable for storage, like a vector or embedding. It manages this by separating a single data point into numerous features and assigning values to each of them. The primary purpose of a vector database is to store and manage these vector embeddings generated by machine learning models.
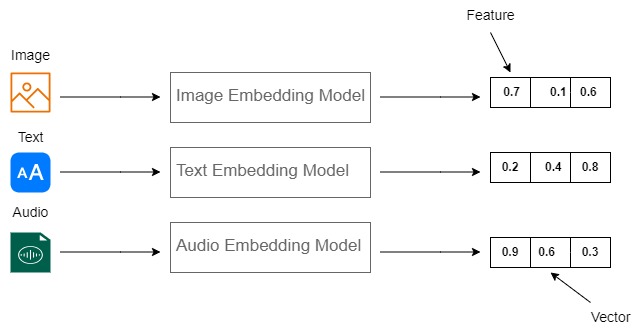
What is Binary Quantization?
In simple terms, binary quantization involves converting each feature of a vector (embedding) into a binary number.
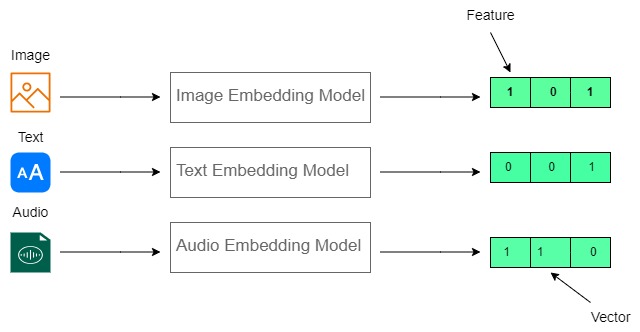
For instance, consider an image represented by three features, each stored as a FLOAT-32 value. Applying binary quantization to this vector would reduce each feature being represented individually by a single binary digit. As a result, the original vector with three FLOAT-32 values is transformed into a vector of three binary digits, such as [1, 0, 1].
Here’s an overview of the process:
1. Creating Vector Embeddings:
First, the data is converted into vector embeddings, which are specialized codes that represent the data in a form that computers can understand and use.
2. Quantizing the Data:
The next step is to convert these codes into a simple binary format from their original, detailed format. Here are the various approaches for reaching this:
- Binary Hashing: This uses hash functions to convert data into binary codes.
- Sign Function: This method assigns a binary value based on whether the number is positive or negative. For example, positive numbers become 1 and negative numbers become 0.
- Thresholding: Here, a cutoff point is set, and numbers are converted to binary based on whether they are above or below this point.
3. Encoding:
After conversion, the data is compressed into a compact binary format, enabling faster storage and processing.
4. Working with Binary Data:
Using binary data makes operations like searching and comparing much faster because binary numbers are simpler for computers to handle than detailed floating-point numbers.
Why do we use Binary Quantization?
The primary reason to use binary quantization is to speed up vector search and retrieval operations, which is crucial in various data-intensive applications. Here’s why it’s so effective:
- Faster Comparisons: Once the data is in binary format, comparison during a search operation becomes much faster. Instead of processing complex numbers, the system only needs to compare simple 0s and 1s, reducing the number of steps required.
- Less Storage Needed: Since binary data requires less storage space, the system can store and process more data simultaneously, resulting in faster operations and reduced system workload.
- Better Performance: For applications that need to handle a lot of data quickly like real-time systems or large databases, every bit of efficiency helps. Binary quantization makes sure these systems run smoothly by making search and retrieval faster.
- Lower Computational Load: Binary quantization simplifies mathematical operations as binary values require fewer resources compared to floating-point numbers. This results in a decreased computational load on systems.
- Enhanced Scalability: As data grows, binary quantization helps systems scale more effectively. Since binary data is more compact, systems can manage larger datasets without a proportional increase in processing power or storage.
Conclusion
In today’s world of big data, where speed is crucial, binary quantization is highly beneficial due to its ability to expedite data processing. It transforms complex data into simple binary numbers, enhancing the speed of searching and retrieving information. Additionally, it reduces storage requirements and improves the system performance. As a result, systems can manage larger volumes of data more efficiently and maintain smooth operations as data grows.


