
GCP BigQuery Benefits
Wondering what the buzz about GCP BigQuery is? Here is what you need to know:
- Accelerated time to value – Users are able to access their data warehousing equipment online without needing expert-level administration in-house. This reduces the extra management required to make the most out of the data
- Simplicity and scalability – Complete all of your data warehousing and analytical tasks through a simple and effective interface, without managing additional infrastructure. You can even scale your system up or down depending on cost, performance and size requirements
- Speed – With Google’s BigQuery solution, data can be scaled rapidly based on need and ingest or export data sets with amazing speed using Google Cloud Platform
- Security – Make sure that all of your projects are encrypted and protected with identity and access management support
- Reliability – Google’s Cloud and BigQuery give you access to always-on available, constant up-time running and geo-replication across a wide selection of Google data centers
Google BigQuery has two payment routes with a transparent flat rate or pay-as-you-go pricing.
High-Level Architecture
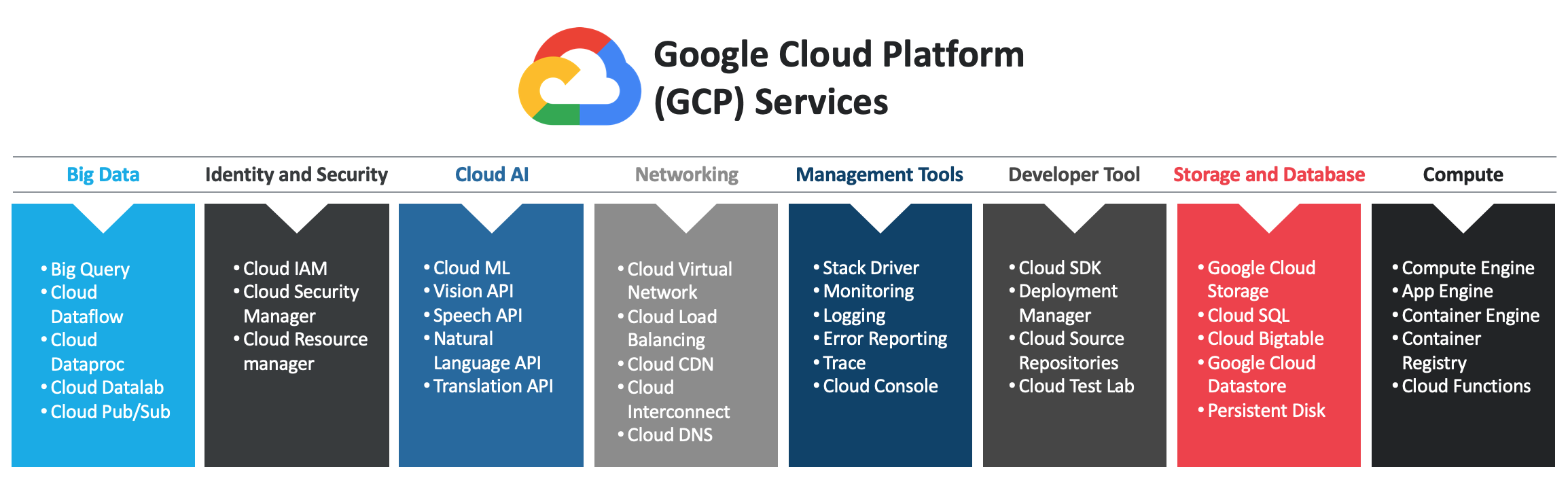
GCP Services
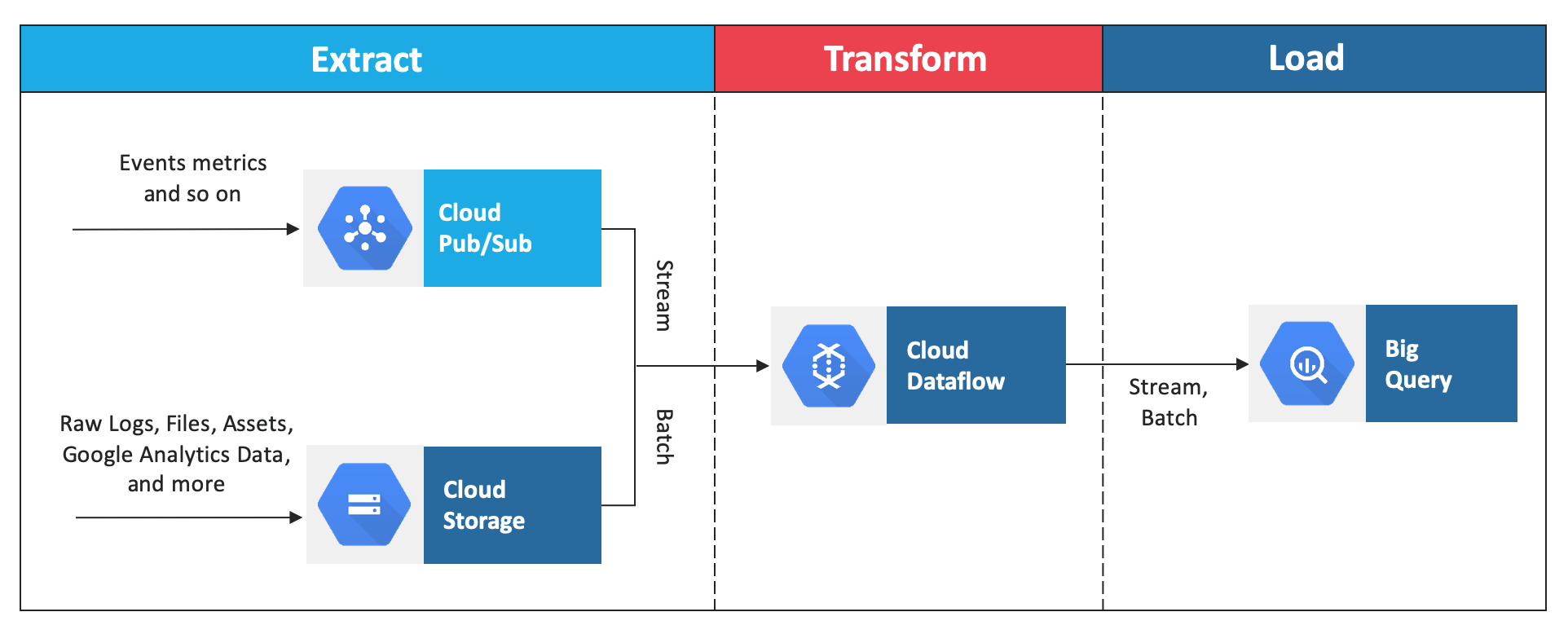
Data Processing Architectures
Google BigQuery is a serverless, highly scalable data warehouse that comes with a built-in query engine. The query engine is capable of running SQL queries on terabytes of data in a matter of seconds and petabytes in minutes. You get performance without managing any infrastructure and there is no need to create or rebuild indexes.
Storage
BigQuery differs from other cloud data warehouses in that queries are served primarily from spinning disks in a distributed file system. Most competitor systems need to cache data nodes in order to get good performance. BigQuery, on the other hand, relies on two systems unique to Google, the Colossus File System and Jupiter Networking, within compute, to ensure that data can be queried quickly no matter where it physically resides in the compute cluster.
ETL Architecture
BigQuery has a native, highly efficient, columnar storage format that makes ETL an attractive methodology. The data pipeline, typically written either in Apache Beam or Apache Spark, extracts the necessary bits from the raw data (either streaming data or batch files), transforms to do any necessary cleanup or aggregation, and then loads it into BigQuery.
If transformation is not necessary, BigQuery can directly ingest standard formats like CSV, JSON, or Avro into its native storage-an EL (Extract and Load) workflow.
*It is recommended to design for an EL workflow if possible, and only drop to an ETL workflow if transformations are needed.
Cloud Dataproc provides the ability to read, process, and write to BigQuery tables using Apache Spark programs.
*Indexing is not necessary – your SQL queries can filter any column in the data set and BigQuery will take care of the necessary query planning and optimization. For the most part, we recommend that you write queries to be clear and readable, and rely on BigQuery to choose a good optimization strategy.



