

Introduction
In a rapidly expanding Apache Kafka-based application, the complexity of consumer processes becomes more intricate and necessitates meticulous optimization. The application handles continuous data streams generated by thousands of sources, often sending records simultaneously. It operates on top of ZooKeeper and is designed for both online and offline message consumption.
Kafka and Its Capabilities
Kafka is an open-source distributed event streaming platform. Originally developed by LinkedIn and later donated to the Apache Software Foundation, Kafka excels in handling large data volumes and enabling message passing between endpoints. It supports both real-time and offline communication consumption.
- Processes millions of messages per second, demonstrating its powerful data-handling capabilities
- Seamlessly integrates with numerous data sources, including various databases
- Acts as an intermediary between source and target systems
- Enables data distribution across multiple waiters and operates with exceptional speed
Architecture of Kafka
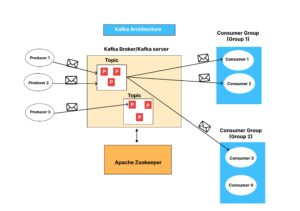
A Kafka broker (server) listens on a specific IP and port (default: 9092) and hosts multiple topics, each with multiple partitions. Producers send messages to these topics, while consumers retrieve them. Consumer groups enable parallel processing, where each consumer belongs to a group and consumes messages from assigned partitions. Kafka supports multiple producers and consumer groups. For instance, Consumer Group 1 and Consumer Group 2 each have two consumers. Consumers within a group share the workload of consuming messages from a topic, while different groups can read the same data independently. Apache ZooKeeper manages metadata, tracks topic configurations, and monitors message consumption. If a partition is added, ZooKeeper updates consumers accordingly, ensuring efficient coordination.
Key Components of Kafka
- Producers: Producers generate data and send it to Kafka topics. All the messages will be appended to a partition. Producers can also send messages to a partition of their choice.
- Consumers: Consumers retrieve data from the Kafka cluster in an ordered way, which maintains the order of dispatches within each separation. This approach ensures consistent and dependable data access.
- Topic: Data is organized within a topic in Kafka. When the producer sends the information to a Kafka content, the consumer gets back that data from the same topic.
- Partition: Each topic can be segmented into multiple partitions, which are spread across various Kafka brokers within a cluster.
- Broker: A broker manages topics by storing data and handling partitions while addressing customer requests. Each broker can contain multiple partitions, enhancing its capacity and effectiveness.
Commands used for Apache Kafka
To Start ZooKeeper server:
zookeeper-server-start.bat D:\Servers\kafka_2.13-2.8.1\config\zookeeper.properties
To Start Kafka server:
kafka-server-start.bat D:\Servers\kafka_2.13-2.8.1\config\server.properties
List of topic:
Kafka-topics.bat –list –zookeeper localhost:2181
Create Topic:
Kafka-topics.bat –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic topicname
Advantages of Kafka
High Throughput: Kafka can handle a high volume of dispatches at a rapid speed, processing thousands of dispatches in a second.
Easily Accessible: Kafka stores all the data, allowing users to access it easily at any time. This storage capability ensures that data is available for retrieval whenever needed.
Scalability: Kafka offers high scalability to manage large amounts of data simultaneously, which positions it as a scalable software solution.
High Availability: Kafka is designed for high availability, ensuring it continues to function even when some brokers become unavailable.
Low Latency: Kafka provides low-latency communication between producers and consumers, which is essential for real-time analytics and monitoring applications.
Integration: Kafka seamlessly integrates with a variety of big data tools, including Hadoop and Spark.
Disadvantages of Kafka
Complexity: Due to its distributed architecture, setting up and configuring Kafka can be complex, especially for beginners.
Do not support wildcard topic selection: Apache Kafka does not support wildcard topic selection, limiting its functionality to exact topic name matching. This lack of flexibility hinders its ability to effectively address certain use cases.
ZooKeeper Dependency: Kafka depends on Apache ZooKeeper for managing and coordinating its distributed cluster.
Security: Kafka lacks some advanced security features like role-based access control, data encryption, and authentication.
Lack of Tools: Enterprise support staff may find it difficult to choose and support Kafka due to the lack of embedded management and monitoring tools.
Conclusion
Apache Kafka is an adaptable platform for real-time data streaming. It efficiently distributes data using directors, consumers, topics, and brokers. However, Kafka’s setup can be complex as it depends on ZooKeeper for cluster management. Despite lacking built-in security and monitoring tools it remains popular due to its performance. Kafka is well-suited for handling large-scale data processing and analytics tasks.



