

Introduction to Qdrant
Qdrant is an open-source and fully managed database that stores, searches, and manages vector data, along with payloads using the convenient API. The similarity and semantic search in a Qdrant means finding the most similar vectors in the database through distance metrics. The Qdrant database supports the three most common distance metrics – cosine similarity, dot product, and euclidean distance.
Qdrant provides different client libraries for different programming languages. They are of the following,
How does Qdrant Store Vectors and Metadata?
The Qdrant database stores the vector data using an optimized data structure that allows efficient storage and retrieval of similar high dimensional data of vectors. The vectors are designed to retrieve fast similar searches with minimum storage requirements.
- Qdrant represents each vector as a set of numerical values (Embedding Values) corresponding to its dimensional values
- The dimension of vectors should be defined while creating the collection. It can vary depending on the specific use case and requirements
- Qdrant employs index-based structure, such as a Hierarchical navigable small world (HNSW). This index structure organizes vectors in a hierarchical manner, allowing for fast nearest neighbor searches and other similar Queries
- Qdrant stores vectors in a combination of in-memory and on-disk storage. The in-memory storage is used for fast Query processing, and on-disk storage is used for handling large datasets
- Qdrant organizes the vector data into segments, which are logical partitions of the dataset. Each segment contains vectors and their payload. The segmentation allows for efficient data retrieval and management
- Qdrant associates metadata (payload) with each vector to provide additional information. This metadata is typically stored alongside vector data for easy retrieval and correlation during search operations
Finding Similar Embeddings using Qdrant
To find similar vectors or embeddings using Qdrant, we have to follow the below steps.
- First, we have to make sure that Qdrant is installed and running on your particular environment
- Now we can create collections with that particular endpoint to insert data like embeddings and payload after creating collections. We can create each collection with a unique name and unique Schema
- We can insert embeddings into a collection created by us. The embeddings should be inserted along with a unique identifier, which can be a string or an integer
- After inserting data into a particular collection, we can perform a similarity search by providing the query embeddings. While providing query embeddings, we have to mention the number of similar embeddings you want to retrieve. For finding similar embeddings over high dimensional data, it uses Indexing techniques like HNSW (Hierarchical Navigable Small World)
Solution Architecture using AKS
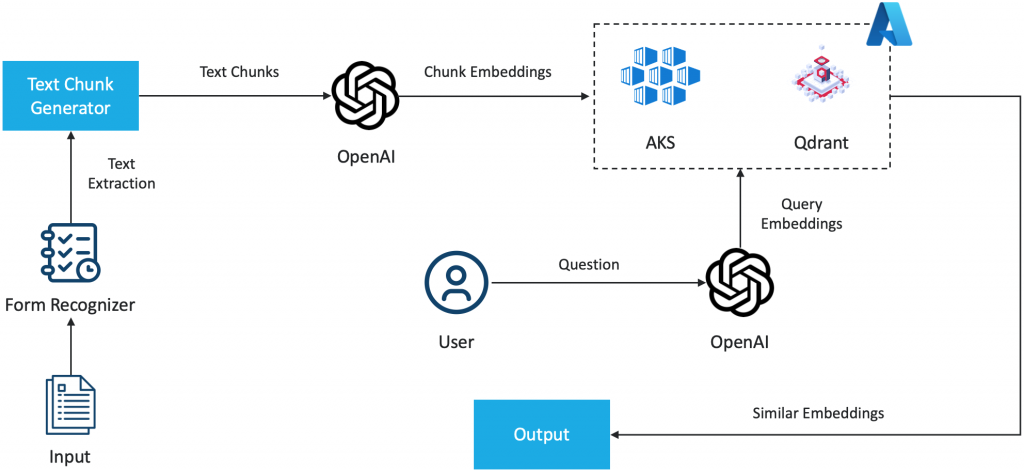
Advantages of Qdrant
- Efficient Similar Search – Qdrant is specially designed for similar search operations. It is very fast and accurate for finding similar embeddings over a high amount of data
- Scalability – Qdrant is scalable because it can efficiently handle large volumes of vectors
- Ease of use – The Qdrant database provides a user-friendly API that makes it easy to set up, insert data, and perform similar searches
- Opensource – Qdrant is an open-source project, which means we have access to the source code and can contribute to its development
- Flexibility – The Qdrant database supports a flexible Schema, which means we can define different types of vector fields and also store and search different types of data such as images, text, audio, and more
Conclusion
Qdrant is a powerful tool that can help businesses unlock the power of semantic embeddings and revolutionize text search. It offers a reliable and scalable solution for managing high-dimensional data with excellent query performance and ease of integration. Its open-source database allows continuous development, fixes bugs, and makes improvements.



