

Google and its parent company Alphabet worked together to create Gemini, hailed as their most advanced AI model. They received substantial support from Google DeepMind in developing Gemini. Recently, Google made a notable advancement by publicly releasing the latest iteration of Gemini, a large language model (LLM). This move is expected to have a significant impact on all of Google’s products due to the substantial advancements in AI that it embodies.
What is Google Gemini?
Google has developed a new and powerful artificial intelligence model called Gemini that can understand not just text but also images, videos, and audio. As a multimodal model, Gemini has the ability to understand and generate highly qualified code in multiple programming languages in addition to completing complex tasks across disciplines like physics, arithmetic, and other subjects.
Is Gemini Available in Multiple Versions?
According to Google, Gemini is a flexible design that can operate on a variety of platforms, including mobile devices and Google’s data centers. It is available in three different sizes – Gemini Pro, Gemini Nano, and Gemini Ultra.
Gemini Pro
Gemini Pro Vision is a large language vision model that can produce pertinent text responses by understanding input from both text and visual modalities (picture and video). One foundation model that excels at several multimodal tasks is Gemini Pro Vision, which can be used for visual understanding, classification, summarization, and content creation from images and videos. It can process text and visual inputs like documents, screenshots, photos, and infographics with ease.
Gemini Nano
The most effective model for on-device operations that need effective AI processing without requiring a server connection is Gemini Nano. Stated otherwise, it is optimized for use with smartphones, namely the Google Pixel 8.
Gemini Ultra
As described by Google, the upcoming Gemini Ultra is touted as the most advanced model, outperforming current state-of-the-art results on 30 out of 32 widely-used academic benchmarks in large language model (LLM) research and development. It is designed for complex tasks and will be released for general use upon completion of the testing phase.
Gemini Architecture
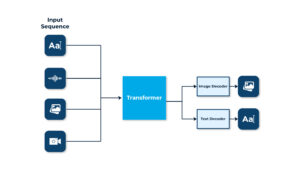
The diagram shows how a transformer model can handle different tasks, including text, audio, and image input modalities. Each input modality is initially encoded by the model into a series of vectors. After processing these vectors, the transformer gains the ability to recognize connections between various modalities. A series of vectors is the transformer’s output, which must be decoded into the appropriate output modality. Input could be an image, while the output may consist of a textual description of the image.
What makes Gemini different from GPT-4 and other AI models?
Google’s latest Gemini model appears to be one of the most advanced AI models so far, but the upcoming release of the Ultra model will provide confirmation. Gemini’s inbuilt multimodal feature sets it apart from other popular models that currently power AI chatbots. Gemini can handle multimodal tasks naturally, unlike GPT-4, which is mostly a text-based model. GPT-4 uses OpenAI’s plugins to perform image analysis and web access, and it uses DALL-E 3 and Whisper to make images and process voice. However, it excels at language-related tasks like content creation and complicated text analysis.
Key Features of Google Gemini
Recognizing Text, Pictures, Voice, and More
The recently developed AI model known as multimodal AI combines several algorithms with different kinds of data to provide better results. As Gemini makes use of this model, it works well with a variety of data formats. More accurate AI interactions are produced, allowing you to contribute text, voice, photos, and other kinds of data.
Reliability, Scalability, and Efficiency
Gemini is said to be five times more powerful than GPT-4 because it makes use of Google’s TPUv5 CPUs. Its enhanced processing capabilities enable it to handle multiple requests simultaneously and handle complex tasks efficiently.
Sophisticated Reasoning
Gemini is trained on a massive text and code dataset, ensuring the model can access the most up-to-date information and provide accurate and reliable responses to your queries. Google states that the model performs better in a variety of intelligence tests such as the MMLU benchmark than both “expert level” humans as well as OpenAI’s GPT- 4.
Advanced Coding
Gemini 1.0 can understand, explain, and generate high-quality code in the most widely used programming languages, such as Python, Java, C++, and Go. This makes it one of the leading foundation models for coding globally.
Few Reasons Behind Gemini’s Popularity
Performance
According to Google, Gemini performs better than ChatGPT in many benchmarks, especially in activities like understanding audio and video and reasoning and problem-solving.
Integration Abilities
The three Gemini versions support many platforms and gadgets, allowing for integration with a wide range of services and apps. Gemini Nano, for instance, is perfect for applications and offline functionality because it can be used on-device. In the near future, Gemini will also be integrated with a number of Google products.
Translating Languages
Gemini can translate written text, spoken words, or even programming code into more than 100 languages, making it a versatile tool for facilitating communication across various language barriers.
Writing Creative Content
Gemini can write different kinds of creative content, such as poems, stories, scripts, musical pieces, email, letters, etc.
Answering Questions
Gemini can answer your questions in an informative way, even if they are open ended, challenging, or strange. Through Google Search, it can retrieve and handle real-world data while maintaining response consistency with search results.
Conclusion
Gemini is a powerful tool with a wide range of applications and significant potential. While still in its initial stages, this technology has the power to completely change how humans interact with computers. Gemini AI has the potential to enhance the complexity and interaction of chatbots, virtual assistants, and other AI-powered software in the future. Additionally, it might improve our understanding of the world by looking through big datasets, discovering developments and finding patterns.



