

Introduction to Vertex AI
Vertex AI is a machine learning service offered in the Google Cloud Platform (GCP). One of its coolest components is Pipelines, which allows you to automate, monitor, and govern Machine Learning systems by orchestrating the ML workflow in a serverless manner. Additionally, you can store the workflow’s artifacts using Vertex ML Metadata, and this enables you to analyze the lineage of workflow artifacts. By storing the artifacts of ML workflow in Vertex ML Metadata, you can gain a better understanding of the workflow and its performance.
What is Kubeflow?
Kubeflow is an open-source Machine Learning toolset that runs on Kubernetes. With Kubeflow, you can create end-to-end Machine Learning models in the form of pipelines. Kubeflow Pipelines is a platform that allows you to build and deploy scalable and portable workflows for Machine Learning using Docker containers. You can analyze various aspects of Kubeflow, including the ease of setup, deploying a model, performance, limitations, and features. Additionally, it provides a Machine Learning Model Orchestration Tool Set that simplifies configuring, monitoring, and maintaining defined pipelines and workflows.
Kubeflow Pipeline Components
- ExampleGen – It is capable of providing data to components, transforming the data, and deploying the targets during inference
- StatisticGen – It calculates statistics for the dataset
SchemaGen – It generates the schema using data statistics and also examines it using the statistics for the train split - ExampleValidator – It detects different classes of Anomalies, and Missing values in the training and serving data
- Transform – It performs feature engineering on the dataset
- Trainer – It trains the model
- Tuner – It tunes the hyperparameters of the model
- Evaluator – It performs a deep analysis of the training results and helps you validate your exported models, ensuring that they are “good enough” to be pushed to production
- InfraValidator – It checks if the model is actually servable from the infrastructure and prevents wrong models from being pushed
- Pusher – The serving infrastructure is the deployment location for Pusher’s model
- BulkInferrer – It performs batch processing on a model with unlabeled inference requests
Kubeflow Pipeline Components Architecture
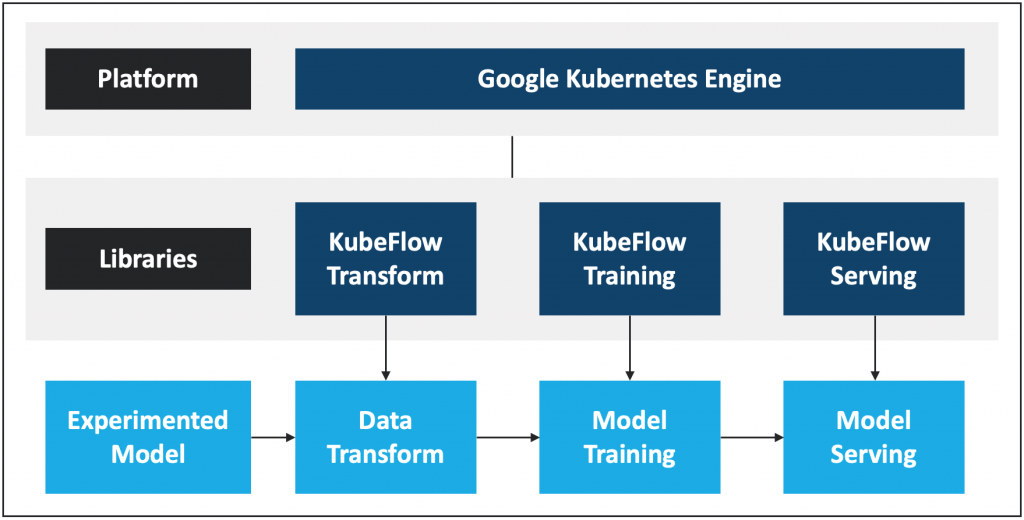
Overview of Pipeline Creation and Architecture of Google Kubeflow Engine
Create a new project in the Google Cloud platform and enable the services for Vertex AI, cloud storage, and Kubernetes Engine API, and install the required Python packages for Kubeflow pipelines to integrate with ML pipelines in Vertex AI. Set up the variables to customize the pipelines by using the GCP project ID, GCP region to run pipelines, and the name of the GCP storage bucket i.e., to store pipeline outputs.
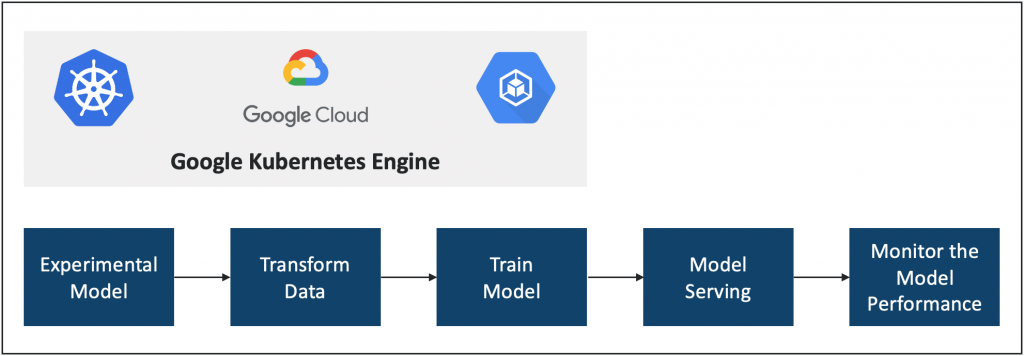
Pre-requisites
- Google Cloud Storage Bucket
- Vertex AI
- Kubernetes Engine APIs
Steps to Create a Kubeflow Pipeline
- Create a Google Cloud project using https://console.cloud.google.com/vertex-ai?project
- Configure the created cloud project with Vertex AI pipelines and also configure the Kubeflow Pipelines
- Enable the Vertex AI, Cloud Storage, and Kubernetes Engine APIs
- Configure a cloud storage bucket for pipeline artifacts
- Go to the Vertex AI workbench and enable Compute Engine API using https://console.cloud.google.com/vertex-ai/workbench/legacy-instances?project
- The first time you run Workbench you will need to enable the Notebooks API, Create a New Notebook, and launch it
- Install Python packages that are required and set up the variables that are related to the project and region
- Create an ML pipeline and set the paths for Pipeline artifact, Python modules, User data, Vertex AI endpoint
- Prepare or Import the dataset and create a Kubeflow pipeline using (Example Gen & Val, Stat Gen, Schema Gen) on Python script in the same notebook
- In the same notebook, a pipeline definition and job (Transform) can be created using a Python script that incorporates Trainer and Pusher
- Run the pipeline on Vertex pipelines by using the Kubeflow orchestrator Python script in the same notebook
- Test with a prediction request by setting the endpoint ID
Kubeflow Pipeline Architecture
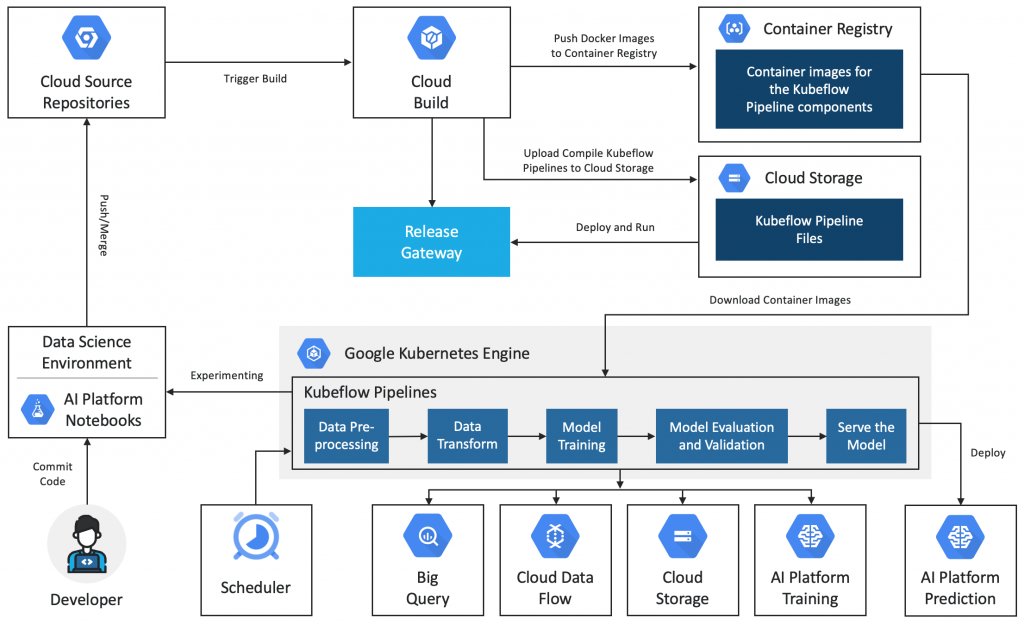
Conclusion
Kubeflow with TFX and Vertex AI is a platform designed to orchestrate complex machine learning workflows that run on Kubernetes. The components present in the Kubeflow pipeline simplify the way you automate and build models on your datasets, leading to better models. Additionally, various GCP platforms, including Cloud Source Repositories, Cloud Build, and Container Registry, can store the results of every step in the Kubeflow pipeline. This makes it easier to track the progress of the workflow and analyze its performance.



