
Introduction
Today, one of the most powerful resources any organization can have is data. A staggering amount of data is generated daily, and most of the time a person is not even aware of the data being generated. Be it smartphones, watches, IoT devices, cars, there are numerous sources that continuously keep on generating data. All of this data has a great value, but the value needs to be created by providing a proper medium to analyze the data.
SQL Server has been one of the most prominent and widely used databases, but now with the advent of cloud computing, there has been a shift to leverage the advantages offered by cloud computing, one of them being Google Cloud Platform. Here, we will be discussing the best practices on migrating MS SQL Server to BigQuery, one of the most popular products offered by Google Cloud Platform.
Pre-Migration
These are some things to be considered before the migration from SQL Server to GCP BigQuery,
- Understand and analyze the use case. BigQuery is a Modern Cloud Data Warehouse solution and not a Relational Database solution. It does not have the concept of primary key, foreign key and would not be the best solution for an OLTP system. For example, you can append a new column to the table but cannot drop a column. The only way to modify a table is to create a new one and load the data from the existing table. So, analyze the current system thoroughly and also refer to the Quotas and Limits of BigQuery at the given link – Link
- Once the decision has been made on migrating to BigQuery, there are two options,
- If the plan includes completely shutting down the on-prem database, then the best option is to shift the data from on-prem to Cloud Storage and then loading the tables as native or external as per the use case
- If the migration to BigQuery is just to leverage the features and performance offered by BigQuery, and the new data would still be loaded into the on-prem database, then there is an option to replicate the database on BigQuery using Cloud Data Fusion (expensive option, but can be considered if the use case demands). This link provides more details about the approach
Migration
Now, once the approach has been chosen for the migration to BigQuery, these are some of the things to be considered,
- Staging Area for Data – Google Cloud Storage
- In most cases, Google Cloud Storage would be used as a staging area before loading the datasets into BigQuery. One thing to be noted is to make sure that the GCS bucket and BigQuery dataset are in the same location
- UTF-8 Encoding
- For csv files, make sure they are UTF-8 encoded as BigQuery by default considers UTF-8 encoding. If not, then make sure to specify the encoding before loading the data to avoid errors
- Handling some commonly encountered errors while loading tables
- BigQuery Auto Schema detection reads the first 100 rows of data and decides the data type of the column, so for some columns it might create an issue due to that. For example, if generally a row has integer values, but at some positions it does have non-integer values, then auto detect might take it as an integer, which should not be the case. In such scenarios, it is better to define the schema than to use auto detect. Also, for manually defined schema, make sure to skip the header row, if not, BigQuery will try to fit it into as a row value and that would cause errors for non-string fields, as generally header rows would be string values
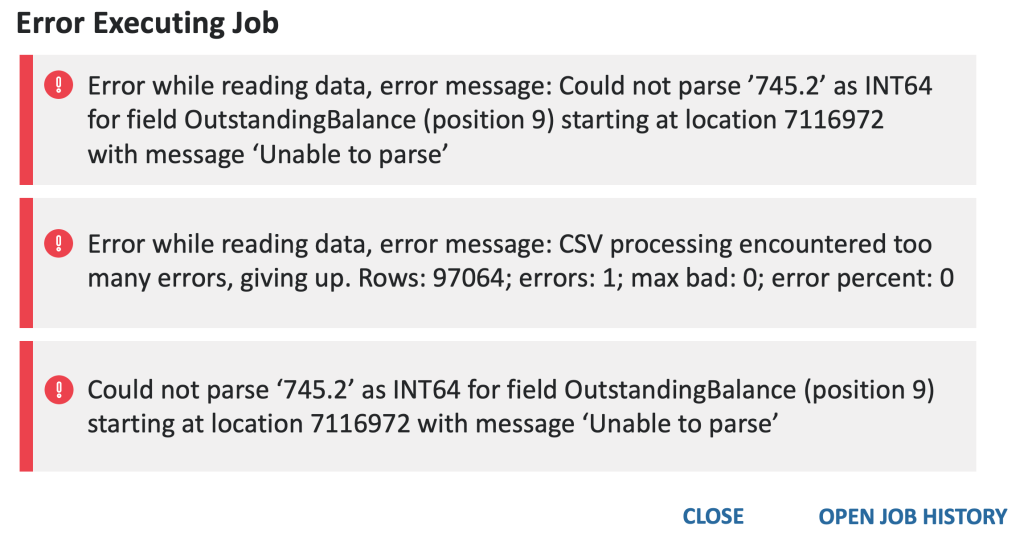
- The other issue that can be faced is if there are columns that have free form text or multiple lines of text in them, then it generates an error like,
Error : Missing close double quote (“) character- One way to solve this is to select the ‘allow quoted new lines’ section in the advanced section, which is shown in the screenshot below. If that does not solve the issue, the other approach is to load the data in Google Sheets and then connect that to BigQuery
- External Table vs Native Table
- If high querying performance is of utmost priority, then choose Native Table and if low storage cost is important, then better to go with External Table. This choice will vary based on use case requirements
Performance Enhancers
Moving on, these are some of the practices that help in saving costs and optimizing performance,
- Denormalizing Schema
- BigQuery is column oriented and is designed to support denormalized data as opposed to normalized data. Although not a requirement, Google recommends denormalizing the schema when the dimension table is large i.e more than 10GB
- Nested and Repeated Fields
- BigQuery supports additional data types for nested fields called STRUCT and ARRAY for repeated fields. These column types help in further enhancing the impact of denormalized schema and are useful in avoiding joins on tables, which are computationally expensive
- Partitioning
- Partitioned tables help in optimizing cost and performance by reducing the amount of data processed by the queries as opposed to scanning full tables
- Most common type of partitioning is done on time related columns, and then the queries can specify filters on those columns to reduce the amount of data scanned
- Clustering
- On clustering a table, the table data is automatically organized based on the column provided. When clustered on multiple columns, the order specified is important. Maximum 4 columns are allowed
- Clustering can improve the performance of queries using filter clauses or aggregating data, as the sorted blocks co-locate rows with similar values
- To see a significant improvement, Google recommends clustering of tables only if the table size is larger than 1GB



