
What would today’s enterprises give to understand their users? Ever-Demanding Consumers and a Customer-Centric market mean that today’s organizations have to enable themselves to look within the sentiments of their users and understand their needs like never before.
The explosion of Social and Mobile has led to huge stores of user data, which helps to explain their patterns, behaviors, and needs. Incorporating these needs into an organizations business model can always help to drive new opportunities.
The Business Challenge
Traditionally companies seeking feedback on their products and services send questionnaires and surveys to their users or try to host a discussion group. This will rather be limited to a handful of people, which might not be always accurate when reflected the entire population set.
Companies need insight from their consumers to answer some of the following questions,
- What type of products do visitors tend to buy?
- Where does our company stand in terms of reputation?
- What features of the product are best used?
- What needs to be changed to improve the quality of the product’s next version?
- How many people the product has reached?
- Whether the service is good, bad (or) ugly?
A New Feedback Model
In today’s digital era, it is important for organizations to be able to utilize the Social and Mobile trends to their advantage. The Digital Enterprise makes it’s business decisions based on data coming from the Internet. With new channels such as Facebook, Twitter and Mobile Apps, the way a user expresses their feelings has completely changed.
With evolving technology, social media has become a one-stop platform for sharing one’s views and experiences. Companies are also increasingly concerned about their overall brand perception online.
People are expressing their thoughts through online blogs, discussion forums, and social media platforms. If we take Twitter as an example, millions of tweets are accumulated every day. If the tweets are analyzed, we can predict the success rate of a product or extract valuable information from them. This will help companies in their market research and even in predicting the future.
Sentiment Analysis
What is Sentiment Analysis? Sentiment Analysis is the process of taking a block of text and determining if the author of that text is showcasing positive, neutral (or) negative about a particular topic. In our use case, we have extended this analysis to Twitter, where we can analyze a user’s sentiment towards an organization based on a customized algorithm, which picks up specific keywords from users tweets.
Understanding your Users
What is the goal of this scenario? Enterprises should be able to make decisions based on the analysis of the user’s sentiment from a collection of tweets.
Twitter is known for its ability to ‘TREND’ the feelings, sentiments, and emotions of users in a large and global scale. Analyzing these tweets based on keywords, usernames and hashtags can help organizations to understand the emotions of their users towards a particular subject.
To extract data from Twitter, a developer can use Twitter’s API. With this tweet, data is crawled from the Twitter Web Page and the developers can extend this code in Java, Python, and many other languages. Despite the capability and simplicity of the Twitter API, it stills needs hands-on development experience and coding, and this can sometimes be a roadblock for enterprises.
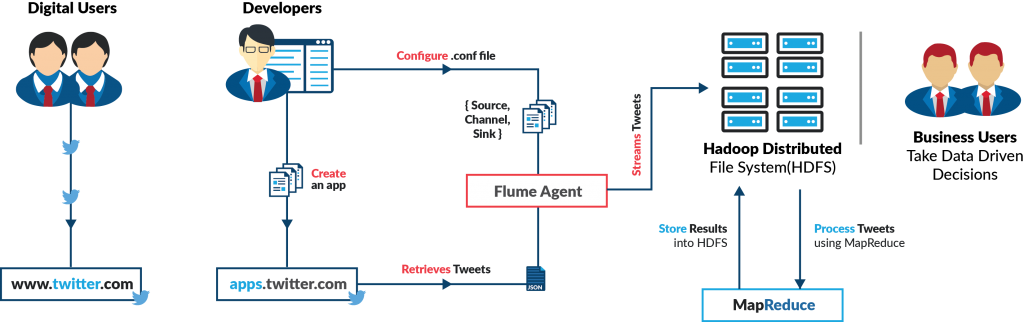
Twitter Apps, Flume, HDFS and MapReduce
Instead, a better approach would be to use Apache Flume, which helps to stream data and from a defined source to a destination in a configuration-based approach. With the simple configuration of a Flume Agent, you can start streaming data from Twitter and land it directly in HDFS (Hadoop Distributed File System).
This scenario uses the following technologies to enable the sentiment analysis model for the enterprise = Twitter Apps, Hadoop Distributed File System (HDFS_, MapReduce and Apache Flume).
The data which is filtered and streamed from Twitter (Based on Keywords and Hashtags) is in JSON format which is difficult to store and retrieve using traditional RDBMS systems. HDFS provides a better storage solution for this unstructured JSON data coming from Twitter, which can then easily be queried upon and analyzed using MapReduce.



