

Introduction
In the era of AI and machine learning, data is more than text or numbers; it is defined by context and relationships. The growth of unstructured data, especially with the rise of embeddings (vectors) generated by natural language models, has necessitated databases that can handle more than basic indexing. Qdrant, a vector database, is designed to handle scalable similarity searches efficiently. This article explores Semantic Cache, one of Qdrant’s powerful capabilities that significantly boosts the performance of vector search and similarity queries.
What is Semantic Cache?
Semantic Cache in Qdrant DB is a specialized caching mechanism designed to accelerate similarity search queries by reusing results from previously executed queries. Instead of saving raw query results like traditional caches, Semantic Cache taps into the unique strengths of vector search.
When searching for similar items based on vector representations, small variations in query vectors can produce vastly different results. Semantic Cache identifies the semantic similarity between two queries, even if their input vectors differ slightly. Intelligently storing and reusing relevant query results reduces the need to recompute similar or near-identical queries, significantly improving response times.
How Does It Work?
Query Vector Matching
The core idea behind Semantic Cache is recognizing similarity rather than relying on exact matches. Qdrant DB uses distance-based metrics such as cosine similarity, Euclidean distance, or Hamming distance to determine the proximity between vectors. When a new query is issued, Qdrant checks whether a semantically similar query has already been cached.
Caching Mechanism
Qdrant stores its vector representation and the corresponding cache results when a query is processed. The next time a similar query is issued, instead of processing it from scratch, Qdrant retrieves the cached results, saving both time and computational resources.
Threshold-based Reuse
Not all queries are cached or reused indiscriminately. Qdrant allows the configuration of a similarity threshold that defines how close two queries must be for the cache to be used. This ensures the results remain accurate and relevant, even when relying on cached data.
Automatic Cache Invalidation
Since embeddings can change over time, Qdrant employs intelligent cache invalidation mechanisms to ensure that stale or irrelevant cache entries are periodically removed, keeping the system up-to-date with the most current data.
Architecture
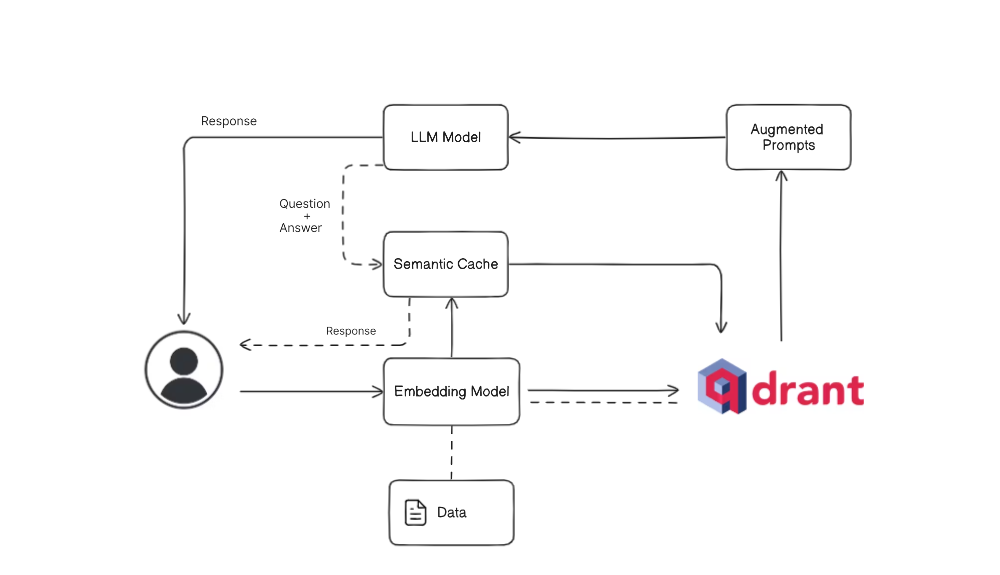
Why Use Semantic Cache in Qdrant DB?
Performance Boost
Vector search is computationally intensive, especially with large datasets and complex models. Semantic Cache significantly reduces the time required to execute frequent or similar queries, making your system more responsive and scalable. This is particularly beneficial for real-time applications such as recommendation engines, chatbots, and fraud detection systems.
Cost Efficiency
By reducing the number of times a query needs to be recalculated, Semantic Cache minimizes the use of compute resources. This leads to lower operational costs, especially in cloud-based environments where compute expenses can quickly accumulate.
Scalability
As your dataset grows, querying becomes increasingly resource-intensive. Semantic Cache enables smoother scalability by optimizing the performance of vector-based queries, ensuring that system responsiveness remains consistent even as the database size increases.
Smarter Caching
Traditional caching systems operate based on exact matches of requests. In contrast, Semantic Cache understands the conceptual similarity between queries, enabling smarter and more efficient cache usage in vector search contexts. This is ideal for AI-driven applications, where queries may not be identical but are conceptually similar enough to reuse results.
Use Cases for Semantic Cache
Personalized Recommendations
E-commerce platforms, streaming services, and content platforms can benefit from Qdrant’s Semantic Cache by quickly retrieving personalized recommendations based on past user interactions, even if the queries vary slightly.
Search Engines with Context Awareness
In search engines that leverage AI for query understanding, Semantic Cache accelerates response times by reusing semantically similar search results, improving the overall user experience.
Chatbots and Conversational AI
Chatbots frequently encounter variations of the same question or intent. By utilizing Semantic Cache, these systems can quickly retrieve relevant responses from previous conversations, enabling dynamic and responsive interactions.
Fraud Detection
Fraud detection systems often rely on pattern recognition across massive datasets. With Qdrant’s Semantic Cache, the system can reuse semantically similar detection patterns, allowing for faster threat identification.
Conclusion
The Semantic Cache in Qdrant DB is a powerful innovation that enhances the speed, efficiency, and intelligence of vector search. By caching and reusing results based on semantic similarity, organisations can optimise their AI-driven applications, ranging from tailored suggestions to cutting-edge search platforms and fraud detection systems. In an era where data-driven insights are crucial, Qdrant’s Semantic Cache is an essential feature for any organization looking to scale AI efficiently.



